1. Une introduction à Node.js▲
Si vous souhaitez découvrir Node et que les connaissances énoncées ci-après vous sont familières, ce document est fait pour vous :
- un langage de script, tel que JavaScript, Ruby, Python, Perl, etc. Si vous n'êtes pas programmeur, vous préférerez sans doute précéder cette lecture par la découverte de JavaScript for Cats
 ;
; - Git et Github qui sont les outils de collaboration privilégiés par la communauté. Rassurez-vous, pas besoin d'être expert, quelques connaissances basiques suffiront. Au besoin, voici trois superbes tutos pour bien démarrer avec git : 1, 2, 3.
2. Apprentissage interactif de Node▲
Par expérience, j'ai appris que la simple lecture d'un guide ne se suffit pas à elle-même. Gardez votre éditeur de texte favori sous la main et écrivez du Node en parallèle ! Apprendre en codant est le meilleur moyen d'intégrer les concepts que vous lirez.
2-1. NodeSchool.io▲
NodeSchool.io est une série d'ateliers open source et gratuits qui vous enseigneront les principes de Node.js, et plus encore pour les curieux !
Learn You The Node.js est le cours introductif aux ateliers NodeSchool.io. Il met en scène les principaux cas d'utilisation de Node.js. Il est conçu pour être utilisé directement en ligne de commande.
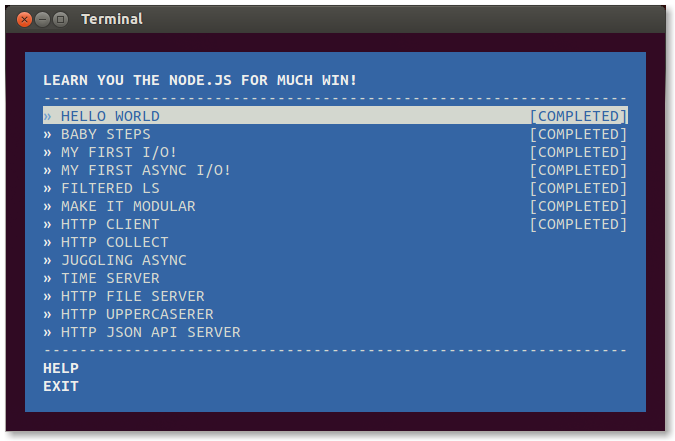
Installez-le avec npm :
# install
npm install learnyouNode -g
# start the menu
learnyouNode3. Comprendre Node▲
Node.js est un projet open source conçu pour vous aider à écrire des programmes JavaScript qui interagissent avec des réseaux, des file systems ou toute autre source d'I/O (entrée/sortie, lecture/écriture). Et c'est tout ! Node n'est qu'une plateforme simple et stable qui vous encourage à construire des modules par dessus.
Avec quelques exemples, tout sera plus clair. Ci-après le diagramme d'une application que j'ai réalisée avec Node et qui présente de nombreuses sources d'I/O :

Rassurez-vous, vous n'avez pas besoin de tout comprendre à ce graphe. Le but est de vous montrer qu'un simple processus Node (l'hexagone au centre) peut agir comme un hub entre les différentes sources d'I/O (en orange et violet sur le diagramme).
Usuellement, produire ce type de système induit deux conséquences probables :
- d'excellentes performances à l'exécution, mais au prix de difficultés dans l'écriture (comme partir de zéro pour écrire un serveur web en C) ;
- une simplicité d'écriture, mais de faibles performances, ou un manque de robustesse (comme quand quelqu'un essaye d'envoyer un fichier de 5 Go sur votre serveur et qu'il crashe).
L'objectif poursuivi par Node est de trouver l'équilibre entre ces deux situations : être accessible tout en offrant des performances optimales.
Attention, Node n'est ni :
- un framework web (comme Rails ou Django, même s'il peut être utilisé pour produire ce genre de chose) ;
- un langage de programmation (il est basé sur JavaScript, mais Node n'est pas son propre langage).
Au lieu de cela, Node se situe quelque part au milieu. On peut dire qu'il est à la fois :
- conçu pour être simple et donc relativement facile à comprendre et utiliser ;
- adapté aux programmes fondés sur des I/O, nécessitant rapidité et capacité à gérer de nombreuses connexions.
À bas niveau, Node peut se décrire comme un outil permettant l'écriture de deux types de programmes majeurs :
- les programmes de Réseaux qui utilisent les protocoles du web´: HTTP, TCP, UDP, DNS et SSL ;
- les programmes qui lisent et écrivent des données dans les file systems, les processus locaux ou en mémoire.
Qu'est-ce qu'un programme « fondé sur des I/O » ? Voici quelques exemples de sources :
- bases de données (e.g. MySQL, PostgreSQL, MongoDB, Redis, CouchDB) ;
- API (e.g. Twitter, Facebook, Notifications Push Apple) ;
- HTTP/connections WebSocket (des utilisateurs d'une application web) ;
- fichiers (redimensionnement d'images, éditeur vidéo, radio Internet).
Node gère les I/O de manière asynchrone ce qui le rend très efficace dans la gestion de processus simultanés. Prenons un exemple : si vous commandez un cheeseburger dans un fast-food, ils prendront votre commande et vous feront patienter le temps que votre plat soit prêt. Pendant ce temps, ils prendront les commandes des autres clients et n'auront aucun mal à démarrer la cuisson de leurs cheeseburgers en parallèle. Maintenant, imaginez un peu si vous deviez attendre votre sandwich au comptoir, empêchant tous les clients derrière vous de commander jusqu'à ce que votre produit soit prêt ! On appelle cela l'I/O Bloquante, car toutes les I/O se produisent les unes après les autres. Node, à contrario, est non bloquant, ce qui signifie qu'il peut cuire plusieurs cheeseburgers à la fois !
Quelques exemples amusants de choses permises par la nature non bloquante de Node :
- contrôler des quadricopters volants ;
- écrire des bots IRC ;
- créer des robots marcheurs bipèdes.
4. Modules de base▲
Pour commencer, je vous suggère d'installer Node sur votre machine. Le plus simple est de vous rendre sur Nodejs.org et de cliquer sur « Install ».
Node possède nativement un petit groupe de modules (qui répond communément au nom de « Node core » - « Cœur de Node ») qui sont présentés en tant qu'API publique, et avec lesquels nous sommes censés écrire nos programmes. Pour travailler avec un file system, il y a le module 'fs', et pour les réseaux, les modules comme net (TCP), http, dgram (UDP).
En sus de fs et des modules de réseau, le cœur de Node propose d'autres modules de base. Il existe un module pour gérer les requêtes DNS de manière asynchrone nommé dns, un autre pour récupérer les informations spécifiques à l'OS comme le chemin d'accès path du tmpdir nommé os, un autre encore pour allouer des morceaux de mémoire nommé buffer, d'autres pour parser les URL et les chemins (url, querystring, path), etc. La plupart, sinon tous, sont là pour gérer le principal cas d'utilisation de Node : écrire rapidement des programmes qui parlent aux file systems et aux réseaux.
Node possède plusieurs cordes à son arc pour gérer les I/O : des callbacks, des évènements, des streams - 'flux' et des modules. Si vous arrivez à apprendre comment ces quatre structures fonctionnent, alors vous serez capable d'aller dans n'importe lequel des modules core de Node, et de comprendre comment vous interfacer avec eux.
4-1. Callbacks▲
Voilà le sujet le plus important si vous voulez comprendre comment utiliser Node. On retrouve les callbacks à peu près partout dans Node. Ils n'ont cependant pas été inventés par Node, ils font simplement partie intégrante de JavaScript.
Les Callbacks sont des fonctions qui s'exécutent de manière asynchrone ou plus tard dans le temps. Au lieu de lire le code de haut en bas de manière procédurale, les programmes asynchrones peuvent exécuter différentes fonctions à différents moments. Cet ordre sera défini en fonction de l'ordre et de la vitesse des précédents appels, comme les requêtes HTTP ou bien encore la lecture du système de fichiers.
Cette différence peut entraîner des confusions, car déterminer si une fonction est asynchrone ou non dépend beaucoup de son contexte. Voici un exemple synchrone, ce qui signifie que vous pouvez lire ce code de haut en bas comme un livre :
var myNumber = 1
function addOne() { myNumber++ } // define the function
addOne() // run the function
console.log(myNumber) // logs out 2Ce code définit une fonction, puis appelle cette fonction, sans attendre quoi que ce soit. Quand la fonction est appelée, elle ajoute immédiatement 1 au nombre. On peut donc s'attendre à ce qu'après l'appel de cette fonction, le nombre soit égal à 2. De manière assez basique donc, le code synchrone s'exécute de haut en bas.
Node en revanche, utilise essentiellement du code asynchrone. Utilisons Node pour lire notre nombre depuis un fichier appelé number.txt :
var fs = require('fs') // require is a special function provided by Node
var myNumber = undefined // we don't know what the number is yet since it is stored in a file
function addOne() {
fs.readFile('number.txt', function doneReading(err, fileContents) {
myNumber = parseInt(fileContents)
myNumber++
})
}
addOne()
console.log(myNumber) // logs out undefined -- this line gets run before readFile is donePourquoi obtenons-nous undefined quand nous affichons le chiffre cette fois-ci ? Dans ce code, nous utilisons la méthode fs.readFile, qui est une méthode asynchrone. Tout ce qui doit parler à un disque dur ou à un réseau aura tendance à être asynchrone. Si leur objectif est simplement d'accéder à la mémoire, ou travailler avec le processeur, alors ils seront synchrones. La raison est que l'I/O est effroyablement lent ! En guise d'illustration, dites-vous que parler avec un disque dur est environ 100 000 fois plus lent qu'une communication avec la mémoire(la RAM).
Quand nous lançons ce programme, toutes ses fonctions sont immédiatement définies, mais elles n'ont pas besoin de s'exécuter immédiatement. C'est un élément fondamental à comprendre en programmation asynchrone. Quand addOne est appelé, il démarre readFile et enchaîne avec le prochain élément prêt à être exécuté. S'il n'y a rien dans la file d'attente, Node attendra les opérations fs/réseau en attente pour terminer, ou il s'arrêtera simplement de tourner et sortira sur la ligne de commande.
Quand readFile aura terminé de lire le fichier (cela peut prendre entre quelques millisecondes et plusieurs minutes, en fonction de la vitesse du disque dur), il lancera la fonction doneReading, puis lui donnera une erreur (s'il y en a une) ainsi que le contenu du fichier.
La raison pour laquelle nous obtenons undefined ci-dessus est qu'il n'existe aucune logique dans notre code pour dire à notre console.log d'attendre que le readFile ait terminé avant de sortir notre chiffre.
Si vous avez du code que vous voulez pouvoir exécuter encore et encore, ou simplement plus tard, la première étape consiste à encapsuler ce code dans une fonction. Ensuite, vous pouvez indiquer à votre fonction le moment où elle devra l'exécuter. Bien évidemment, donner des noms descriptifs et verbeux à vos fonctions aidera grandement.
Les Callbacks ne sont que des fonctions qui s'exécutent plus tard. La clef pour comprendre les Callbacks est de réaliser que vous ne savez pas quand une opération asynchrone sera terminée, mais vous savez où cette opération doit se compléter – la dernière ligne de votre fonction asynchrone ! L'ordre haut en bas de déclaration de vos Callbacks n'a pas d'importance, seule l'encapsulation logique compte. Commencez par découper votre code en fonctions, puis utilisez vos callbacks pour déclarer qu'une fonction requiert qu'une autre se termine.
La méthode fs.readFile fournie par Node est asynchrone et il se trouve qu'elle prend beaucoup de temps pour se terminer. Mettez-vous à sa place : elle doit aller interroger l'OS, qui à son tour doit se renseigner auprès du file système, qui vit sur le disque dur, qui n’est pas forcément lancé à des milliers de tours par minute. Ensuite il doit utiliser un laser pour lire une donnée, puis la renvoyer à travers toutes les strates successives de votre programme JavaScript. Vous donnez donc à readFile une fonction (aussi appelé Callback) qu'il appellera une fois qu'il aura récupéré les données de votre système de fichiers. Il placera les données qu'il a récupérées dans une variable JavaScript et appellera votre Callback avec cette variable. Dans ce cas, la variable est nommée fileContents, car elle a pour valeur le contenu du fichier qui a été lu.
Reprenez l'exemple du restaurant cité au début de ce tutoriel. Très souvent, vous trouverez dans les restaurants des numéros à poser sur votre table pendant que vous patientez. Ces numéros sont comme des Callbacks. Ils indiquent au serveur ce qu'il doit faire une fois que votre sandwich est prêt.
Plaçons maintenant notre console.log dans une fonction et passons-la en Callback.
var fs = require('fs')
var myNumber = undefined
function addOne(callback) {
fs.readFile('number.txt', function doneReading(err, fileContents) {
myNumber = parseInt(fileContents)
myNumber++
callback()
})
}
function logMyNumber() {
console.log(myNumber)
}
addOne(logMyNumber)La fonction logMyNumber peut désormais être passée en argument qui deviendra la variable de Callback dans la fonction addOne. Une fois que readFile en a terminé, la variable Callback sera invoquée (callback()). Seules les fonctions peuvent être invoquées, donc si vous passez n'importe quoi d'autre qu'une fonction, il en résultera une erreur.
Quand une fonction est invoquée en JavaScript, le code qu'elle renferme est immédiatement exécuté. Dans notre cas, notre console log s'exécutera puisque callback est logMyNumber. Rappelez-vous, le simple fait de define une fonction ne signifie pas qu'elle s'exécutera. Pour ce faire, vous devez invoke une fonction.
Pour aller encore plus loin avec cet exemple, voici une liste chronologique des évènements qui se produisent à l’exécution de ce code :
- Le code est parsé, ce qui signifie qu'une quelconque erreur syntaxique casserait le programme. Durant cette phase initiale, il y a quatre choses qui sont définies: fs, myNumber, addOne, et logMyNumber. Notez qu'elles sont simplement définies. Aucune fonction n'a encore été invoquée pour le moment ;
- Quand la dernière ligne de notre programme est exécutée addOne est invoquée, puis est passée dans la fonction logMyNumber comme « callback », ce qui est bien ce que nous demandons quand addOne est terminée. Cela entraîne immédiatement le démarrage de la fonction asynchrone fs.readFile. Cette partie du programme prend un peu de temps à se terminer ;
- Puisqu'il n'a rien à faire, Node patiente pendant que readFile se termine. S'il y avait une quelconque autre tâche à réaliser, Node serait disponible pour faire le boulot ;
- readFile se termine et appelle son callback, doneReading, qui à son tour incrémente le nombre et invoque immédiatement la fonction qu'addOne a passée, logMyNumber (son Callback).
La chose la plus troublante quand on programme avec des Callbacks est probablement le fait que les fonctions sont de simples objets, encapsulables dans des variables et que l'on peut passer n'importe où avec des noms différents. Affecter des noms simples et descriptifs à vos variables est primordial pour rendre votre code lisible pour les autres comme pour vous-même. D'une manière générale, si vous voyez une variable comme callback ou cb, vous pouvez partir du principe qu'il s'agit d'une fonction.
Vous avez peut-être entendu les termes de « evented programming » (programmation évènementielle) ou « event loop » (boucle d'évènements). Ils réfèrent à la manière dont readFile est implémentée. Node dispatche d'abord les opérations readFile puis attend que readFile envoie un évènement qu'il a clôturé. Pendant qu'il patiente, Node peut tranquillement s'affairer ailleurs. Pour s'y retrouver, Node maintient une liste de tâches qui ont été dispatchées, mais qui n'ont pas encore reçu de feedback, et boucle dessus indéfiniment jusqu'à ce que l'une d'entre elles soit terminée. Lorsque c’est chose faite, Node invoque les éventuels Callbacks qui lui sont rattachés.
Voilà une version de l'exemple précédent en pseudo-code :
function addOne(thenRunThisFunction) {
waitAMinuteAsync(function waitedAMinute() {
thenRunThisFunction()
})
}
addOne(function thisGetsRunAfterAddOneFinishes() {})Imaginez que vous ayez trois fonctions asynchrones a, b et c. Chacune d'elles prend environ une minute à être complétée puis lance un Callback (qui se voit passé en premier argument). Si vous vouliez dire à Node : « lance a, puis b une fois que a est terminé, puis c une fois que b est terminé », cela ressemblerait à :
Quand ce code est exécuté, a démarrera immédiatement, puis une minute plus tard il appellera b, qui une minute plus tard lancera c. Au bout de trois minutes, Node s'arrêtera puisqu'il n'y aura plus rien à faire. Bien évidemment, il existe des méthodes plus élégantes pour écrire le code ci-dessus, mais le but est de montrer que si vous avez du code qui doit attendre un autre code asynchrone pour s'exécuter, alors il faut exprimer cette dépendance en disposant votre code dans une fonction qui sera alors passée comme Callback.
Le design de Node requiert un mode de pensée non linéaire. Considérez donc cette liste d'opérations :
- lire un fichier ;
- traiter ce fichier.
Si vous transformiez cela en pseudo-code vous obtiendriez :
var file = readFile()
processFile(file)Ce type de code non linéaire (étape par étape, dans l'ordre) n'est pas la manière dont Node fonctionne. Si ce code devait être exécuté, alors readFile et processFile devraient être lancées au même moment. Cela n'aurait aucun sens puisque readFile mettra du temps à se terminer. À la place, vous devez signifier que processFile dépend de readFile. C'est exactement à cela que servent les Callbacks ! Et parce que JavaScript fonctionne ainsi, vous pourrez écrire cette dépendance de plusieurs manières :
var fs = require('fs')
fs.readFile('movie.mp4', finishedReading)
function finishedReading(error, movieData) {
if (error) return console.error(error)
// do something with the movieData
}Mais vous pourriez aussi structurer votre code de cette façon et il fonctionnerait toujours :
var fs = require('fs')
function finishedReading(error, movieData) {
if (error) return console.error(error)
// do something with the movieData
}
fs.readFile('movie.mp4', finishedReading)Ou même comme ceci :
5. Évènements▲
Dans le cas où vous auriez besoin du module d'évènement, Node vous propose event emitter, un module utilisé nativement par Node pour l'ensemble des ses API.
L'utilisation d’évènements est chose très commune en programmation, plus connue en tant que patron de conception Observation ou encore 'Observateur/Observable'. Tandis que les Callbacks sont des relations une à une entre la chose qui attend le Callback et celle qui appelle ce Callback, les évènements répondent au même schéma, à l'exception de leur système relationnel plusieurs à plusieurs.
La manière la plus simple d'imaginer les évènements est de considérer qu'ils vous permettent de vous abonner à quelque chose. Vous pouvez dire : « Quand X, fait Y », alors qu'un Callback fonctionnera en « Fait X puis Y ».
Ci-après une liste de cas d'utilisation où l'on privilégiera les évènements sur l'utilisation de Callbacks :
- canaux de discussion pour envoyer un message à un grand nombre d'observateurs ;
- serveurs de jeux qui nécessitent de savoir quand de nouveaux joueurs se connectent, déconnectent, se déplacent, sautent ou tirent ;
- moteur de jeux où vous voulez permettre aux développeurs de souscrire à des évènements comme .on('jump', function() {}) ;
- serveur web bas niveau où l'on veut exposer une API pour facilement accrocher des évènements comme .on('incomingRequest') ou .on('serverError').
Si nous voulions écrire un module qui se connecte à un serveur de chat en utilisant uniquement des Callbacks, cela ressemblerait à cela :
var chatClient = require('my-chat-client')
function onConnect() {
// have the UI show we are connected
}
function onConnectionError(error) {
// show error to the user
}
function onDisconnect() {
// tell user that they have been disconnected
}
function onMessage(message) {
// show the chat room message in the UI
}
chatClient.connect(
'http://mychatserver.com',
onConnect,
onConnectionError,
onDisconnect,
onMessage
)Comme vous pouvez le constater, cette méthode est particulièrement lourde, car il faut passer toutes les fonctions dans un ordre spécifique à la fonction .connect. Avec une écriture évènementielle, nous obtiendrions ceci :
var chatClient = require('my-chat-client').connect()
chatClient.on('connect', function() {
// have the UI show we are connected
})
chatClient.on('connectionError', function() {
// show error to the user
})
chatClient.on('disconnect', function() {
// tell user that they have been disconnected
})
chatClient.on('message', function() {
// show the chat room message in the UI
})L'approche est similaire à la version en Callbacks, mais introduit les méthodes .on, qui rattachent des callbacks à un évènement. Ce qui signifie que vous pouvez choisir à quel évènement vous voulez souscrire depuis le chatClient. Vous pouvez aussi écouter le même évènement à de multiples reprises avec différents Callbacks :
6. Flux▲
Plus tôt dans le projet Node, le système de fichiers et les API de réseaux avaient leurs schémas de fonctionnement séparés pour gérer les flux d'I/O. Par exemple, les fichiers du système de fichiers avaient des descripteurs de fichiers, le module fs nécessitait de la logique supplémentaire pour garder des traces de toutes ces choses, tandis que les modules de réseau ignoraient ces concepts. En dépit de différences sémantiques mineures comme celles-ci, au niveau fondamental, les deux groupes de code dupliquaient beaucoup de fonctionnalités quand il s'agissait de lire les données en entrée et en sortie. Les équipes développant Node ont réalisé qu'il serait confus d'avoir à apprendre deux groupes sémantiques pour faire relativement la même chose ; ils ont alors créé une nouvelle API nommée Stream à la fois pour le système de fichiers et le réseau.
Tout l’intérêt de Node réside dans sa capacité à faciliter l'interaction avec les systèmes de fichiers et les réseaux, il était donc censé d'avoir un seul schéma de fonctionnement valable pour toutes les situations. La bonne nouvelle est que la plupart des cas d'utilisation (et ils sont peu nombreux quoi qu'il en soit) ont été couverts par Node, et il est fort peu probable que Node évolue de ce côté à l'avenir.
Il y a deux ressources formidables pour commencer à apprendre l'utilisation des flux Node. La première est stream-adventure (cf. Apprentissage de Node Interactif), et la seconde s'appelle Stream Handbook.
6-1. Stream Handbook▲
stream-handbook est un guide, similaire à celui-ci, qui contient des références sur absolument tout ce que vous pouvez avoir besoin de savoir sur les flux.
7. Modules▲
Le cœur de Node est composé d'une douzaine de modules. Certains de bas niveau comme events ou flux, d'autres de plus haut niveau comme http et crypto.
Ce design est intentionnel. Node core est supposé être léger, et les modules core doivent s’en tenir à fournir les outils nécessaires au traitement usuel des protocoles I/O, de manière cross-platform.
Pour tout le reste, il y a npm. Tout le monde peut créer de nouveaux modules qui ajoutent quelques fonctionnalités et les publier sur npm. Au moment où j’écris ces lignes, il y a 34 000 modules sur npm.
7-1. Comment trouver un module ?▲
Imaginez que vous souhaitez convertir un fichier PDF en TXT. Le meilleur moyen est de commencer par chercher npm search pdf :

Et il y a des tonnes de résultats ! npm est relativement populaire, et vous trouverez généralement de multiples solutions potentielles pour vos besoins. Si vous filtrez suffisamment bien vos résultats, vous devriez vous retrouver avec ceci :
- hummus - manipulateur pdf c++ ;
- mimeograph - API d’agglomération d'outils (poppler, tesseract, imagemagick etc.) ;
- pdftotextjs - wrapper autour de pdftotext ;
- pdf-text-extract – un autre wrapper autour de pdftotext ;
- pdf-extract - wrapper autour de pdftotext, pdftk, tesseract, ghostscript ;
- pdfutils - wrapper poppler
- scissors – API haut niveau wrapper de pdftk, ghostscript ;
- textract - wrapper pdftotext
- pdfiijs - pdf à index inversé en utilisant textiijs et poppler ;
- pdf2json - pure js pdf vers json.
Beaucoup de ces modules ont des fonctionnalités similaires, mais présentent des API alternatives. Ils requièrent aussi très souvent des dépendances externes comme apt-get install poppler.
Voici une approche pour interpréter ces différents modules :
- pdf2json est le seul rédigé en pur JavaScript, ce qui signifie qu'il est aussi le plus simple à installer, notamment sur des petites configurations comme un Raspberry Pi ou un Windows ou le code natif n'est pas nécessairement multiplateforme ;
- les modules comme mimeograph, hummus et pdf-extract combinent chacun de multiples modules bas niveau pour exposer une API haut niveau ;
- beaucoup de ces modules semblent reposer sur les outils de commande Unix pdftotext/poppler.
Comparons les différences entre pdftotextjs et pdf-text-extract, tous deux étant fondés sur l'utilitaire pdftotext.

Tous deux possèdent :
- des mises à jour récentes ;
- des liens vers des dépôts Github (indispensable !) ;
- des fichiers README ;
- une bonne popularité ;
- une licence libre (tout le monde peut les utiliser librement).
En ne regardant que le package.json et les statistiques du module, il est difficile de se faire une bonne idée du meilleur choix possible. Comparons les fichiers README :

Les deux possèdent des descriptions simples, des instructions d'installation, des badges CI, des exemples clairs pour lancer les tests. Fantastique ! Mais lequel devons-nous utiliser ? Comparons le code :

pdftotextjs contient environ 110 lignes de code, contre 40 pour pdf-text-extract, mais les deux peuvent essentiellement se réduire à cette ligne :
var child = shell.exec('pdftotext ' + self.options.additional.join(' '));Est-ce que cela en rend un meilleur que l'autre ? Difficile à dire ! Il est indispensable de lire le code pour tirer vos propres conclusions. Si vous trouvez un module qui vous plaît, lancez npm star modulename pour donner votre feedback à npm.
7-2. Workflow de développement modulaire▲
npm diffère de la plupart des gestionnaires de paquets par sa capacité à installer des modules dans des répertoires contenus à l’intérieur de modules déjà existants. Même si vous n'y voyez pas encore d'intérêt, c'est là la clef du succès de npm.
Beaucoup de gestionnaires de paquets installent les choses de manière globale. Par exemple, si vous lancez apt-get install couchdb sur Debian Linux, il essayera d'installer la dernière version stable de CouchDB. Si vous essayez d'installer CouchDB en tant que dépendance d'un autre logiciel, et que ce logiciel nécessite une version antérieure de CouchDB, vous devrez désinstaller la version la plus récente de CouchDB puis installer la version historique. Vous ne pouvez donc pas avoir deux versions de CouchDB en parallèle, car Debian ne sait installer les modules qu'à un endroit.
Et il n'y a pas que Debian qui fait cela. La plupart des gestionnaires de paquets des langages de programmation fonctionnent ainsi. Pour résoudre ce problème, des environnements virtuels ont été développés comme virtualenv pour Python ou bundler pour Ruby. Ceux-ci découpent votre environnement en plusieurs environnements virtuels, un pour chaque projet. Toutefois, à l’intérieur de chacun de ces environnements, tout reste installé de manière globale. Les environnements virtuels n'adressent donc pas une réponse satisfaisante à notre problème et augmentent qui plus est le niveau de complexité de notre installation.
Avec npm, l'installation de modules globaux est contre nature. De la même manière que vous ne devriez pas utiliser de variable globale dans vos programmes JavaScript, vous ne devriez pas installer de modules globaux (à moins que vous ayez besoin d'un module avec un exécutable binaire dans votre PATH global, ce qui est loin d'être systématiquement le cas – nous en reparlerons).
7-2-1. Comment fonctionne require▲
Quand vous faites appel à require('some_module') voilà ce qui se passe dans Node :
- Si un fichier qui s'appelle some_module.js existe dans le dossier courant, Node le lancera ;
- Autrement, Node recherchera un dossier nommé Node_modules dans le répertoire en cours, contenant un fichier some_module à l’intérieur ;
- S’il ne trouve toujours pas, il montera d'un niveau et répétera l'opération 2.
Ce cycle se répétera jusqu'à ce que Node atteigne le dossier root du système de fichiers. À ce moment, il continuera sa recherche dans les répertoires de modules globaux (comme /usr/local/Node_modules sur Mac OS). Enfin, s'il ne trouve toujours rien, il enverra une erreur.
Pour illustrer ceci, voilà un exemple :

Quand le dossier de travail en cours est subsubfolder et que require('foo') est appelé, Node va chercher un dossier subsubsubfolder/Node_modules. Dans le cas présent, sa recherche sera infructueuse, car le répertoire y est nommé par erreur my_modules. Node va donc remonter d'un répertoire et recommencer son opération, ce qui signifie qu'il cherchera alors subfolder_B/Node_modules qui n'existera toujours pas. Enfin, la troisième tentative passera puisque folder/Node_modules existe bel et bien et possède un répertoire nommé foo en son sein. Si foo n'y était pas, Node aurait continué sa recherche jusqu'aux répertoires globaux.
Notez que s'il est appelé depuis subfolder_B, Node ne trouvera jamais subfolder_A/Node_modules, car il ne peut voir folder/Node_modules que dans sa phase de remontée de l'arborescence.
Un des atouts de l'approche de npm est que les modules peuvent installer leurs dépendances à des endroits spécifiques à leur version. Dans ce cas, le module foo est plutôt populaire – il y en a trois copies, chacune à l’intérieur de son dossier parent. Une explication pourrait être que chaque module parent requiert une version différente de foo, par exemple « folder » qui requiert foo@0.0.1, subfolder_A de foo@0.2.1, etc.
Maintenant, voilà ce qui se produit si nous corrigeons notre problème de nom en remplaçant my_modules par son nom valide Node_modules :

Pour tester quel module est véritablement chargé par Node, vous pouvez utiliser require.resolve('some_module') qui vous montrera le chemin d'accès du module que Node trouve dans sa remontée de l'arborescence. require.resolve est particulièrement utile pour vérifier que le module que vous pensez être chargé l'est véritablement – parfois il y aura une autre version du même module qui sera plus proche de votre répertoire de travail actuel.
7-3. Comment écrire un module▲
Maintenant que vous savez trouver un module et le require, vous pouvez écrire vos propres modules.
7-3-1. Le module le plus simple du monde▲
La légèreté des modules de Node est radicale. En voici l'un des plus simples possibles :
package.json:
{
"name": "number-one",
"version": "1.0.0"
}
index.js:
module.exports = 1Par défaut, Node essaie de lancer module/index.js quand il lit require('module'). Aucun autre nom de fichier ne fonctionnera à moins que vous ne spécifiiez au champ main de package.json de pointer dessus.
Placez les deux fichiers dans un dossier nommé number-one (l'id dans package.json doit matcher un nom de dossier) et vous aurez un module Node fonctionnel.
En appelant la fonction require('number-one') vous retournez la valeur qui est « set » dans module.exports

Un moyen encore plus rapide de créer un module serait de lancer les commandes Shell suivantes :
mkdir my_module
cd my_module
git init
git remote add git@github.com:yourusername/my_module.git
npm initLa commande npm init créera automatiquement un package.json valide pour vous. Si vous lancez un dépôt git existant, il définira tout aussi automatiquement package.json à l’intérieur.
7-3-2. Ajout de dépendances▲
Un module peut lister n'importe quel autre module depuis npm ou GitHub dans le champ dépendances de package.json. Pour installer un module request en tant que nouvelle dépendance et l'ajouter automatiquement au package.json, vous pouvez lancer ceci depuis votre répertoire root :
npm install --save requestCela installera une copie de request dans le Node_modules le plus proche et notre package.json ressemblera ainsi à cela :
{
"id": "number-one",
"version": "1.0.0",
"dependencies": {
"request": "~2.22.0"
}
}Par défaut npm install récupérera la dernière version publiée du module.
7-4. Développez côté client avec npm▲
npm est victime d'un vice de pensée assez fréquent. Node faisant partie de son nom, il est courant de penser qu'il ne gère que des modules JS côté serveur, ce qui est absolument faux ! npm signifie « Node Packaged Module », c'est-à-dire des modules que Node package pour vous. Ces modules peuvent être n'importe quoi. Ce ne sont que des répertoires ou des fichiers encapsulés dans des fichiers .tar.gz et un fichier nommé package.json qui explicite la version du module ainsi que la liste de toutes ses dépendances (ainsi que leurs propres versions de modules pour que seules les versions connues pour fonctionner avec notre module ne soient installées automatiquement). Les dépendances ne sont que des modules, qui peuvent eux-mêmes avoir des dépendances, et ainsi de suite.
browserify est un utilitaire écrit en Node qui tente de traduire n'importe quel module Node en code lisible par un navigateur. Bien que beaucoup de modules soient compatibles, tous ne le sont pas (les navigateurs ne peuvent par exemple pas héberger un serveur HTTP).
Pour essayer npm en navigateur, vous pouvez utiliser RequireBin, qui est une application que j'ai réalisée et qui tire profit de Browserify-CDN. Elle utilise browserify en interne et renvoie la sortie à travers HTTP (en lieu et place de la ligne de commande communément utilisée par browserify).
Essayez maintenant de mettre ce code dans RequireBin et lancez le bouton de preview :
var reverse = require('ascii-art-reverse')
// makes a visible HTML console
require('console-log').show(true)
var coolbear =
" ('-^-/') \n" +
" `o__o' ] \n" +
" (_Y_) _/ \n" +
" _..`--'-.`, \n" +
" (__)_,--(__) \n" +
" 7: ; 1 \n" +
" _/,`-.-' : \n" +
" (_,)-~~(_,) \n"
setInterval(function() { console.log(coolbear) }, 1000)
setTimeout(function() {
setInterval(function() { console.log(reverse(coolbear)) }, 1000)
}, 500)Ou testez un exemple plus complexe (vous êtes libre de changer le code pour voir ce qu'il produit) :
|
|
8. Suivez le mouvement▲
Comme tous les bons outils, Node est particulièrement adapté à certains cas d'utilisation. Par exemple: Rails, le framework web populaire, est fantastique pour modéliser de la logique métier complexe, c'est-à-dire utiliser le code pour représenter des objets métier comme des comptes clients, des prêts, des itinéraires, ou encore des stocks. Même s'il est techniquement possible de faire la même chose avec Node, nous rencontrerions quelques désagréments, car Node n'a pas été conçu pour résoudre ce type de problématiques. Retenez que chaque outil se concentre sur des problèmes différents ! Fort heureusement, ce guide vous aidera à comprendre les forces de Node afin que vous sachiez intuitivement à quel moment y avoir recours.
8-1. Quelles sont les limites du champ d’application de Node ?▲
Node n'est fondamentalement conçu que pour gérer les I/O à travers le système de fichiers et les réseaux, et laisse les fonctionnalités plus fantaisistes aux modules tiers. Voici quelques exemples de choses qui dépassent le périmètre d'action de Node.
8-1-1. Frameworks Web▲
Il existe des frameworks web basés sur Node (framework signifiant un agglomérat de solutions qui cherchent à résoudre des problèmes de haut niveau comme de la logique métier), mais Node n'est pas un framework à lui seul. Les frameworks web conçus par dessus Node ne prennent pas les mêmes décisions concernant l'ajout de complexité, d'abstraction ou de compromis que Node, et ont souvent d'autres priorités que les simples problématiques d'I/O.
8-1-2. Syntaxe du langage▲
Node utilise JavaScript et adopte donc sa syntaxe. Felix Geisendörfer présente une synthèse plutôt bonne du 'style Node' ici.
8-1-3. Niveau d'abstraction du langage▲
Quand cela est possible, Node utilisera le moyen le plus simple d'accomplir quelque chose. Plus fantaisiste sera votre JavaScript, plus vous apportez de complexité. Programmer est difficile, particulièrement en JavaScript où vous avez 1000 manières différentes de résoudre un même problème ! C'est pourquoi Node essaye toujours d'utiliser la solution la plus simple et universelle. Si vous tentez de résoudre un problème qui appelle une solution complexe, et que vous n'êtes pas satisfait des solutions en pur JS que Node implémente, vous êtes libre de les résoudre à l’intérieur de votre module en utilisant le niveau d'abstraction que vous souhaitez.
Un exemple parfait pour cela est l'utilisation que Node fait des Callbacks. Par le passé, Node a fait l’expérience d'une fonctionnalité nommée 'promesses' qui ajoutait un certain nombre de caractéristiques pour rendre le code asynchrone plus linéaire. Les promesses furent retirées du cœur Node pour plusieurs raisons :
- elles sont plus complexes que les Callbacks ;
- elles peuvent être implémentées avec userland (distribué en module tiers via npm).
Considérez une des choses les plus universelles et basiques proposées par Node : lire un fichier. Quand vous lisez un fichier, vous voulez être au courant de l'apparition d'une erreur, comme lorsque votre disque dur meurt au milieu d'une lecture. Si Node possédait des promesses, tout le monde devrait produire un code comme ceci :
fs.readFile('movie.mp4')
.then(function(data) {
// do stuff with data
})
.error(function(error) {
// handle error
})Cela ajouterait de la complexité, et tout le monde ne souhaite pas cela. À la place de deux fonctions différentes, Node n'appelle qu'une fonction de Callback. Les règles sont les suivantes :
- quand il n'y a pas d'erreur, passez null en premier argument ;
- quand il y a une erreur, passez-la en premier argument ;
- le reste des arguments peut être utilisé pour ce que vous désirez (en général les données ou réponses de vos flux d'I/O, puisque vous utiliserez généralement Node à cette fin).
En conséquence, voilà le style Node en Callback :
fs.readFile('movie.mp4', function(err, data) {
// handle error, do stuff with data
})8-1-4. Threads/fibers/non-event-based concurrency solutions▲
Note : si vous ne savez pas ce que ces choses signifient, il sera probablement plus simple d'apprendre Node, puisque désapprendre constitue tout autant de travail qu'apprendre.
Node utilise des threads internes pour accélérer les choses, mais ne les expose pas à l'utilisateur. Si vous êtes un utilisateur technique et que vous demandez pourquoi Node est conçu ainsi, alors vous devriez absolument lire the design of libuv, la couche I/O en C++ sur laquelle Node est fondé.
9. Licence▲

Creative Commons Attribution License (do whatever, just attribute me) http://creativecommons.org/licenses/by/2.0/.
10. Note de la Rédaction de Developpez.com▲
Ce tutoriel est la traduction de The Art of Node - An introduction to Node.js. Nous tenons à remercier Christophe pour la mise au gabarit et -Flot- pour la relecture orthographique.
