






I. Introduction ▲
Les flux se sont imposés à nous dès les premiers jours d'UNIX et se sont montrés à travers le temps comme un moyen incontournable d'agréger de gros systèmes, à partir de composants élémentaires suivant le principe du père d'UNIX, faire une chose et la faire bien. Sur UNIX, les flux sont implémentés par le shell avec le symbole | (pipe). Sur node, les primitives d'accès du module stream sont utilisées par les bibliothèques de son noyau, mais sont également disponibles pour les développeurs. Comme sur UNIX, la première méthode de ce module se nomme .pipe() et apporte un mécanisme qui accélère les écritures pour les clients lents.
Les flux peuvent aider au découplage des problématiques dans la mesure où ils permettent de restreindre la surface d'implémentation à une interface cohérente et réutilisable. De cette façon, on peut connecter la sortie d'un flux sur l'entrée d'un autre, et utiliser des bibliothèques qui opèrent de façon abstraite sur les flux afin d'instituer un pilotage de haut niveau de ceux-ci.
Les flux sont une composante importante de la conception par programmes modulaires et de la philosophie UNIX, mais il existe beaucoup d'autres abstractions qui méritent d'être prises en considération. Gardons à l'esprit que la dette technique est l'ennemi, et qu'il faut toujours garder la meilleure abstraction à portée de main.
II. Pourquoi devrions-nous utiliser des flux ▲
Les E/S en node sont asynchrones, aussi interagir avec le disque ou le réseau implique de passer par des fonctions de callback. Vous pourriez être tenté d'écrire un code pour charger un fichier depuis le disque comme ceci :
var http = require('http');
var fs = require('fs');
var server = http.createServer(function (req, res) {
fs.readFile(__dirname + '/data.txt', function (err, data) {
res.end(data);
});
});
server.listen(8000);Ce code fonctionne, mais il est lourd et garde en mémoire tampon l'intégralité du fichier data.txt pour chaque requête avant de retourner le résultat aux clients. Si data.txt est très volumineux, votre programme pourrait alors consommer une quantité importante de mémoire en fonction du nombre d'utilisateurs, et ce serait d'autant plus avéré pour des utilisateurs à bas débit.
L'expérience utilisateur est également pauvre, car les utilisateurs devront attendre que le fichier soit bufférisé en entier sur le serveur avant de pouvoir recevoir le moindre contenu.
Par chance, les deux arguments (req, res) sont des flux, ce qui signifie que nous pouvons rendre ce code bien plus efficace en utilisant fs.createReadStream() au lieu de fs.readFile() :
var http = require('http');
var fs = require('fs');
var server = http.createServer(function (req, res) {
var stream = fs.createReadStream(__dirname + '/data.txt');
stream.pipe(res);
});
server.listen(8000);Ici .pipe() prend soin d'écouter les événements 'data' et 'end' en provenance de fs.createReadStream(). Ce code n'est pas seulement plus propre, mais maintenant le fichier data.txt sera envoyé aux clients au fur et à mesure de la réception depuis le disque.
L'utilisation de .pipe() présente aussi d'autres bénéfices, comme le contrôle de flux automatique afin que node ne bufférise pas les blocs en mémoire gratuitement, quand un client distant dispose d'une connexion à bas débit ou présentant des temps de latence importants.
Besoin de compression ? Il existe également des modules de streaming pour ça !
var http = require('http');
var fs = require('fs');
var oppressor = require('oppressor');
var server = http.createServer(function (req, res) {
var stream = fs.createReadStream(__dirname + '/data.txt');
stream.pipe(oppressor(req)).pipe(res);
});
server.listen(8000);Maintenant notre fichier est compressé pour les navigateurs qui supportent gzip ou deflate ! Nous pouvons laisser oppressor gérer la mécanique d'encodage du contenu.
Une fois que vous aurez appris l'API stream, vous n'aurez plus qu'à assembler ces modules de streaming comme des briques de Lego au lieu de devoir se rappeler comment pousser des données via des API personnalisées et non adaptées au streaming.
Les flux rendent la programmation node simple, élégante et modulaire.
III. Les bases▲
Il y a cinq types de flux : readable, writable, transform, duplex et classic.
III-A. Les tubes (pipes)▲
Tous les différents types de flux utilisent .pipe() pour appairer les entrées avec les sorties.
.pipe() n'est qu'une fonction qui prend un flux source en lecture src et branche sa sortie sur un flux destination en écriture dst :
src.pipe(dst).pipe(dst) retourne dst afin que vous puissiez chaîner de multiples appels .pipe() ensemble :
a.pipe(b).pipe(c).pipe(d)qui est équivalent à
a.pipe(b);
b.pipe(c);
c.pipe(d);ce qui est beaucoup plus comparable à ce que vous pourriez faire en ligne de commande pour enchaîner les programmes ensemble :
a | b | c | dSauf que ça fonctionne en shell, pas avec node !
III-B. Flux readable▲
Les flux en lecture produisent des données qui peuvent être injectées dans un flux writable, transform ou duplex en appelant .pipe() :
readableStream.pipe(dst)III-B-1. Créer un flux en lecture ▲
Créons un flux readable !
var Readable = require('stream').Readable;
var rs = new Readable;
rs.push('beep ');
rs.push('boop\n');
rs.push(null);
rs.pipe(process.stdout);$ node read0.js
beep booprs.push(null) indique au consommateur que rs est prêt à envoyer des données.
Notez qu'ici, nous avons envoyé du contenu au flux en lecture rs avant de le brancher sur process.stdout, mais le message complet à tout de même été écrit.
C'est parce que, quand vous faites un .push() sur un flux en lecture, les blocs de données que vous envoyez sont stockés dans un tampon jusqu'à ce qu'un client soit prêt à les lire.
Cependant, ce serait encore mieux dans de nombreuses circonstances, si nous pouvions éviter de mettre en mémoire les données et les générer uniquement lorsque le client les demande.
On peut injecter des blocs à la demande en définissant une fonction ._read :
var Readable = require('stream').Readable;
var rs = Readable();
var c = 97;
rs._read = function () {
rs.push(String.fromCharCode(c++));
if (c > 'z'.charCodeAt(0)) rs.push(null);
};
rs.pipe(process.stdout);$ node read1.js
abcdefghijklmnopqrstuvwxyzIci nous injectons les lettres de 'a' à 'z' inclus, mais uniquement lorsque le client est prêt à les lire.
La fonction _read prendra également un paramètre optionnel size comme premier argument qui spécifiera le nombre d'octets que le consommateur souhaite lire. Mais notre flux en lecture peut ignorer le paramètre size s'il le souhaite.
Notez que nous pouvons aussi utiliser util.inherits() pour obtenir une sous-classe héritée de flux readable, mais cette approche se prête peu à des exemples compréhensibles.
Pour montrer que notre fonction _read n'est appelée qu'à la demande du client, nous pouvons légèrement modifier le code de notre flux en lecture pour ajouter un délai :
var Readable = require('stream').Readable;
var rs = Readable();
var c = 97 - 1;
rs._read = function () {
if (c >= 'z'.charCodeAt(0)) return rs.push(null);
setTimeout(function () {
rs.push(String.fromCharCode(++c));
}, 100);
};
rs.pipe(process.stdout);
process.on('exit', function () {
console.error('\n_read() called ' + (c - 97) + ' times');
});
process.stdout.on('error', process.exit);À l'exécution de ce programme, nous pouvons voir que _read() est appelé seulement cinq fois lorsque nous ne demandons que cinq octets en sortie :
$ node read2.js | head -c5
abcde
_read() called 5 timesLe délai du setTimeout est nécessaire en raison du temps nécessaire au système d'exploitation pour nous envoyer le signal pertinent de clôture du pipe.
Le gestionnaire process.stdout.on('error', fn) est aussi nécessaire au système d'opération qui enverra un SIGPIPE à notre processus quand head ne sera plus intéressée par la sortie de notre programme, qui est émis comme un signal d'erreur EPIPE sur process.stdout.
Ces complications supplémentaires sont nécessaires quand on s'interface avec les tubes d'un système d'exploitation, mais sont automatiques lorsque l'on s'interface avec des flux node, c'est-à-dire la plupart du temps.
Si vous voulez créer un flux en lecture qui injecte des valeurs au lieu de simples chaînes de caractères, assurez-vous de créer votre flux en lecture avec Readable({ objectMode: true }).
III-B-2. Consommer un flux en lecture▲
La plupart du temps, il est plus facile de brancher un flux en lecture sur un autre type de flux ou sur un flux créé avec un module tel que through ou concat-stream, mais occasionnellement, il pourrait être utile de consommer directement un flux en lecture.
process.stdin.on('readable', function () {
var buf = process.stdin.read();
console.dir(buf);
});$ (echo abc; sleep 1; echo def; sleep 1; echo ghi) | node consume0.js
<Buffer 61 62 63 0a>
<Buffer 64 65 66 0a>
<Buffer 67 68 69 0a>
nullLorsque des données sont disponibles, l'événement 'readable' se déclenche et vous pouvez appeler .read() pour aller chercher des données dans le tampon.
Quand le flux est terminé, .read() retourne null, car il n'y a plus d'octets à aller chercher.
Vous pouvez aussi appeler .read(n) pour retourner des données sur n octets. Lire un nombre d'octets est purement consultatif et ne fonctionne pas pour des flux d'objets, mais toutes les bibliothèques du noyau le supportent.
Ici, un exemple d'utilisation de.read(n) pour buffériser stdin en blocs de trois octets :
process.stdin.on('readable', function () {
var buf = process.stdin.read(3);
console.dir(buf);
});À l'exécution, cet exemple nous donne des données incomplètes !
$ (echo abc; sleep 1; echo def; sleep 1; echo ghi) | node consume1.js
<Buffer 61 62 63>
<Buffer 0a 64 65>
<Buffer 66 0a 67>C'est parce qu'il y a des données supplémentaires laissées dans les tampons internes et nous devons donner un coup de pied à node, pour lui dire que nous sommes intéressés par plus des trois octets que nous avons déjà reçus. Un simple .read(0) nous donnera cela :
process.stdin.on('readable', function () {
var buf = process.stdin.read(3);
console.dir(buf);
process.stdin.read(0);
});Maintenant notre code fonctionne comme on le souhaite par blocs de trois octets !
$ (echo abc; sleep 1; echo def; sleep 1; echo ghi) | node consume2.js
<Buffer 61 62 63>
<Buffer 0a 64 65>
<Buffer 66 0a 67>
<Buffer 68 69 0a>Vous pouvez aussi utiliser .unshift() pour récupérer les données afin que la même logique de lecture s'applique lorsque la fonction .read() vous retourne plus de données que vous n'en demandiez.
L'utilisation de .unshift() nous évite de faire des copies inutiles de tampon. Ici, nous pouvons construire un parseur en lecture pour afficher ligne par ligne :
var offset = 0;
process.stdin.on('readable', function () {
var buf = process.stdin.read();
if (!buf) return;
for (; offset < buf.length; offset++) {
if (buf[offset] === 0x0a) {
console.dir(buf.slice(0, offset).toString());
buf = buf.slice(offset + 1);
offset = 0;
process.stdin.unshift(buf);
return;
}
}
process.stdin.unshift(buf);
});$ tail -n +50000 /usr/share/dict/american-english | head -n10 | node lines.js
'hearties'
'heartiest'
'heartily'
'heartiness'
'heartiness\'s'
'heartland'
'heartland\'s'
'heartlands'
'heartless'
'heartlessly'Cependant, il existe des modules sur npm tels que split au lieu d'implémenter votre propre logique dans les fonctions de callback.
III-C. Les flux en écriture ▲
Un flux en écriture est un flux que l'on peut passer en paramètre à un .pipe(), mais à partir duquel on ne peut pas invoquer cette méthode :
src.pipe(writableStream)III-C-1. Créer un flux en écriture ▲
Il suffit de définir une fonction ._write(chunk, enc, next) pour pouvoir lui connecter un flux en lecture :
var Writable = require('stream').Writable;
var ws = Writable();
ws._write = function (chunk, enc, next) {
console.dir(chunk);
next();
};
process.stdin.pipe(ws);$ (echo beep; sleep 1; echo boop) | node write0.js
<Buffer 62 65 65 70 0a>
<Buffer 62 6f 6f 70 0a>Le premier argument, chunk représente les données qui sont écrites par le producteur.
Le deuxième argument enc est une chaîne de caractères avec un encodage de type string, mais uniquement lorsque opts.decodeString est à la valeur false et que vous avez écrit une chaîne de caractères.
Le troisième argument, next(err) est une fonction de retour qui indique au client qu'il peut continuer d'écrire des données. Vous pouvez optionnellement passer un objet err, qui émet un événement sur l'instance de flux.
Si le flux en lecture depuis lequel vous vous branchez écrit des chaînes de caractères, ces dernières seront converties en Buffers, sauf si vous créez votre flux en écriture avec Writable({ decodeStrings: false }).
Si le flux en lecture depuis lequel vous vous branchez écrit des objets, créez votre flux en écriture avec Writable({ objectMode: true }).
III-C-2. Écrire sur un flux en écriture ▲
Pour écrire sur un flux en écriture, il suffit d'appeler .write(data) avec la data que vous voulez écrire !
process.stdout.write('beep boop\n');Pour indiquer au flux en écriture de destination que vous avez fini d'écrire, invoquez simplement la méthode .end(). Vous pouvez aussi appeler .end(data) pour écrire data avant de terminer.
var fs = require('fs');
var ws = fs.createWriteStream('message.txt');
ws.write('beep ');
setTimeout(function () {
ws.end('boop\n');
}, 1000);$ node writing1.js
$ cat message.txt
beep boop
Si vous vous préoccupez des débordements de tampon, .write() retourne false quand il y a plus de données que l'option opts.highWaterMark passée à Writable() dans le buffer entrant.
Si vous voulez attendre que le tampon se vide à nouveau, écoutez un événement 'drain'.
III-D. Les flux de transformation▲
Les flux de transformation sont une catégorie de flux duplex (à la fois en lecture et écriture). La différence vient du fait que dans un flux de transformation, la sortie est en quelque sorte calculée depuis l'entrée.
Vous pourrez aussi entendre parler de flux de transformation sous le nom de flux traversants.
Les flux traversants sont de simples filtres lecture/écriture qui transforment une entrée et produisent une sortie.
III-E. Les flux duplex▲
Les flux duplex sont en lecture/écriture et les deux extrémités du flux sont partie prenante d'un dialogue dans les deux sens, envoyant des messages en avant et en arrière comme un téléphone. Un dialogue RPC est un bon exemple de flux duplex. À chaque fois que vous verrez des choses comme : a.pipe(b).pipe(a), vous aurez affaire à un flux duplex.
III-F. Les flux classiques▲
Les flux classiques sont les anciennes interfaces qui apparurent en premier dans node 0.4. Vous rencontrerez probablement ce genre de flux pendant un bon moment, aussi il est bon de savoir comment ils fonctionnent.
Sitôt qu'un flux s'est abonné à un écouteur d'événements « données », il bascule en mode classique et se comporte conformément à l'ancienne API.
III-F-1. Les flux classiques en lecture▲
Les flux classiques en lecture sont juste des émetteurs d'événements « données » quand ils ont des données prêtes pour leurs clients ; ils émettent « end » lorsqu'ils ont fini de produire pour leurs clients.
.pipe() vérifie si un flux classique est en lecture en vérifiant que stream.readable vaut « true ».
Voici un flux des plus simples, en lecture, qui affiche de A à J, inclus :
var Stream = require('stream');
var stream = new Stream;
stream.readable = true;
var c = 64;
var iv = setInterval(function () {
if (++c >= 75) {
clearInterval(iv);
stream.emit('end');
}
else stream.emit('data', String.fromCharCode(c));
}, 100);
stream.pipe(process.stdout);$ node classic0.js
ABCDEFGHIJPour lire depuis un flux en lecture, vous vous abonnez à un écouteur d'événements "data" et "end". Voici un exemple de lecture depuis process.stdin en utilisant les anciens flux de lecture :
process.stdin.on('data', function (buf) {
console.log(buf);
});
process.stdin.on('end', function () {
console.log('__END__');
});$ (echo beep; sleep 1; echo boop) | node classic1.js
<Buffer 62 65 65 70 0a>
<Buffer 62 6f 6f 70 0a>
__END__Notez que dès que vous vous abonnez à un écouteur d'événements "data", vous basculez le flux en mode compatibilité et perdez ainsi le bénéfice de la nouvelle API streams2.
Vous ne devriez plus jamais vous abonner vous-même à des gestionnaires d'événements "data" et "end". Si vous avez besoin d'interagir avec des flux historiques, préférez l'utilisation de bibliothèques sur lesquelles vous pouvez employer .pipe() quand c'est possible.
Par exemple, vous pouvez utiliser through pour éviter de mettre en place des écouteurs "data" et "end" :
var through = require('through');
process.stdin.pipe(through(write, end));
function write (buf) {
console.log(buf);
}
function end () {
console.log('__END__');
}$ (echo beep; sleep 1; echo boop) | node through.js
<Buffer 62 65 65 70 0a>
<Buffer 62 6f 6f 70 0a>
__END__ou utiliser concat-stream pour buffériser le contenu entier du flux :
var concat = require('concat-stream');
process.stdin.pipe(concat(function (body) {
console.log(JSON.parse(body));
}));$ echo '{"beep":"boop"}' | node concat.js
{ beep: 'boop' }Les flux classiques en lecture disposent de primitives .pause() et .resume() pour mettre provisoirement en attente un flux, mais cela reste purement facultatif. Si vous utilisez .pause() and .resume() avec des flux classiques en lecture, vous devriez utiliser through pour gérer la bufférisation au lieu d'écrire cela vous-même.
III-F-2. Flux classiques en écriture▲
Les flux classiques en écriture sont très simples. Définissez juste .write(buf), .end(buf) et .destroy().
.end(buf) peut prendre un paramètre buf ou n'en prendre aucun, mais la communauté node s'attend à ce que stream.end(buf) signifie stream.write(buf); stream.end() et vous devrez vous conformer à ses attentes.
IV. Pour en savoir plus▲
- Documentation core stream
- Vous pouvez utiliser le module readable-stream pour rendre votre code streams2 compatible avec node 0.8 et en dessous, mettez juste require('readable-stream') à la place de require('stream') après votre installation npm 'readable-stream'.
V. Les flux primitifs▲
Ces flux font partie de node lui-même.
V-A. Process▲
V-A-1. process.stdin▲
Ce flux en lecture contient le flux d'entrée système standard de votre programme.
Il est en attente par défaut, mais la première fois que vous vous référerez à lui, .resume() sera implicitement appelé au prochain tick.
Si process.stdin est le clavier (vérifier avec tty.isatty()), alors les événements d'entrée seront bufférisés ligne par ligne. Vous pouvez désactiver le traitement ligne par ligne en appelant process.stdin.setRawMode(true), mais le gestionnaire par défaut des combinaisons de touches telles que ^C et ^D sera supprimé.
V-A-2. process.stdout▲
Ce flux en écriture contient le flux de sortie standard en écriture du système pour votre programme. Écrivez dessus si vous voulez envoyer des données sur la sortie standard.
V-A-3. process.stderr▲
Ce flux en écriture contient le flux d'erreurs standard du système pour votre programme. Écrivez dessus si vous voulez envoyer des données sur la sortie d'erreurs standard.
V-A-4. Net▲
Cette fonction retourne un flux duplex en se connectant en TCP à un hôte distant.
Vous pouvez commencer à écrire directement sur le flux et les écritures seront bufférisées jusqu'au déclenchement de l'événement 'connect'.
VI. Les flux de contrôle▲
VI-A. concat-stream▲
concat-stream accumulera les données du flux dans un unique buffer. concat(cb) prend une unique fonction de callback .cb(body) avec le 'body' bufférisé quand le flux a fini.
Par exemple, dans ce programme, la fonction de 'callback' concat se déclenche avec la chaîne de caractères « beep boop » dès que cs.end() est appelé. Le programme prend ce corps de texte et le met en majuscules, affichant alors « BEEP BOOB »
var concat = require('concat-stream');
var cs = concat(function (body) {
console.log(body.toUpperCase());
});
cs.write('beep ');
cs.write('boop.');
cs.end();$ node concat.js
BEEP BOOP.Voici un exemple d'utilisation d'un concat-steam qui parsera les données d'un formulaire entrant encodées dans l'URL et renverra les données de celui-ci en JSON « stringifié ».
var http = require('http');
var qs = require('querystring');
var concat = require('concat-stream');
var server = http.createServer(function (req, res) {
req.pipe(concat(function (body) {
var params = qs.parse(body.toString());
res.end(JSON.stringify(params) + '\n');
}));
});
server.listen(5005);$ curl -X POST -d 'beep=boop&dinosaur=trex' http://localhost:5005
{"beep":"boop","dinosaur":"trex"}VII. Les flux d'état▲
VII-A. Les Scuttlebut (ragots)▲
Les scuttlebut (ragots) peuvent être utilisés pour de la synchronisation d'état en peer-to-peer sur des topologies de réseau dans lesquelles les nœuds ne sont connectés qu'à travers des intermédiaires, et où aucun nœud ne dispose d'une version de référence de toutes les données.
Ce genre de réseau peer-to-peer distribué que scuttlebutt fournit est particulièrement utile quand les nœuds de part et d'autre d'une barrière de réseaux ont besoin de partager et de mettre à jour un même état.
Un exemple de ce genre de réseau serait des navigateurs qui s'envoient des messages via un serveur HTTP, qui fait tourner des processus auxquels les navigateurs ne peuvent pas se connecter directement. Un autre cas d'utilisation serait celui des systèmes qui étendent les réseaux internes puisque les adresses IPV4 sont insuffisantes.
Si scuttlebut utilise un protocole bavard (gossip protocol) pour échanger des messages entre les nœuds connectés, c'est afin que l'état à travers tous les nœuds finisse par converger partout vers la même valeur.
En utilisant l'interface scuttlebutt/model, nous pouvons créer des nœuds et les connecter entre eux pour créer toutes les sortes de réseaux que nous voulons :
var Model = require('scuttlebutt/model');
var am = new Model;
var as = am.createStream();
var bm = new Model;
var bs = bm.createStream();
var cm = new Model;
var cs = cm.createStream();
var dm = new Model;
var ds = dm.createStream();
var em = new Model;
var es = em.createStream();
as.pipe(bs).pipe(as);
bs.pipe(cs).pipe(bs);
bs.pipe(ds).pipe(bs);
ds.pipe(es).pipe(ds);
em.on('update', function (key, value, source) {
console.log(key + ' => ' + value + ' from ' + source);
});
am.set('x', 555);Le réseau que nous avons créé est un graphe non orienté qui ressemble à :
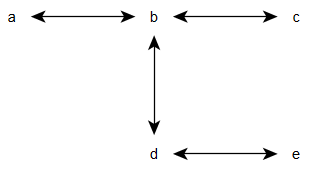
Notons que les nœuds a et e ne sont pas directement connectés, mais lorsque nous exécutons ce script :
$ node model.js
x => 555 from 1347857300518la valeur que le nœud a impose trouve son chemin via les nœuds b et d. Ici tous les nœuds sont dans le même processus, mais parce que scuttlebutt utilise une simple interface de flux, les nœuds peuvent être placés sur n'importe quel processus ou serveur et connectés avec n'importe quel flux de transports qui peut prendre en charge une chaîne de caractères.
Dans un second temps, nous pouvons donner un exemple plus réaliste qui connecte au réseau et implémente une variable compteur.
Voici le serveur qui initialisera la variable count à 0 et l'incrémentera toutes les 320 millisecondes, imprimant toutes les mises à jour du compteur :
var Model = require('scuttlebutt/model');
var net = require('net');
var m = new Model;
m.set('count', '0');
m.on('update', function (key, value) {
console.log(key + ' = ' + m.get('count'));
});
var server = net.createServer(function (stream) {
stream.pipe(m.createStream()).pipe(stream);
});
server.listen(8888);
setInterval(function () {
m.set('count', Number(m.get('count')) + 1);
}, 320);Maintenant nous pouvons écrire le client qui se connecte au serveur, met à jour le compteur et imprime toutes les mises à jour qu'il reçoit :
var Model = require('scuttlebutt/model');
var net = require('net');
var m = new Model;
var s = m.createStream();
s.pipe(net.connect(8888, 'localhost')).pipe(s);
m.on('update', function cb (key) {
// wait until we've gotten at least one count value from the network
if (key !== 'count') return;
m.removeListener('update', cb);
setInterval(function () {
m.set('count', Number(m.get('count')) + 1);
}, 100);
});
m.on('update', function (key, value) {
console.log(key + ' = ' + value);
});Le client est légèrement plus malin, puisqu'il pourrait attendre jusqu'à ce qu'il reçoive une mise à jour de quelqu'un d'autre pour débuter la mise à jour du compteur lui-même, voire réinitialiser son compteur à zéro.
Une fois que le serveur et quelques clients tournent, nous devrions voir une séquence de ce type :
count = 183
count = 184
count = 185
count = 186
count = 187
count = 188
count = 189Plus rarement, sur certains nœuds, nous pourrions observer une séquence avec des valeurs qui se répètent comme :
count = 147
count = 148
count = 149
count = 149
count = 150
count = 151Ces valeurs sont dues à l'algorithme historique de scuttlebutt de résolution des conflits avec lequel il est difficile de garantir un état du système à travers des nœuds parfaitement cohérents.
Notez que le serveur, dans cet exemple, n'est qu'un nœud de plus avec les mêmes privilèges que les clients avec lesquels il est connecté. Les termes clients et serveur, ici, n'affectent en rien la façon dont la synchronisation est effectuée, mais juste celui qui initie la connexion. Les protocoles ayant cette propriété sont souvent appelés protocoles symétriques (cf. dnode pour d'autres exemples de protocoles symétriques).
VIII. Les streams parser▲
VIII-A. JSONStream▲
Utilisez ce module pour parser et « stringifier » des données JSON depuis un flux.
Si vous avez besoin d'envoyer une collection JSON volumineuse en passant par une liaison bas débit ou si vous avez un objet qui se peuplera lentement, ce module vous permettra de parser les données au fur et à mesure de leur arrivée.
IX. Les flux rpc ▲
IX-A. dnode▲
dnode vous permet d'appeler des fonctions distantes à travers tout type de flux.
Voici un serveur dnode basique :
var dnode = require('dnode');
var net = require('net');
var server = net.createServer(function (c) {
var d = dnode({
transform : function (s, cb) {
cb(s.replace(/[aeiou]{2,}/, 'oo').toUpperCase())
}
});
c.pipe(d).pipe(c);
});
server.listen(5004);Maintenant, vous pouvez écrire un simple client qui appelle la fonction .transform() de ce serveur :
var dnode = require('dnode');
var net = require('net');
var d = dnode();
d.on('remote', function (remote) {
remote.transform('beep', function (s) {
console.log('beep => ' + s);
d.end();
});
});
var c = net.connect(5004);
c.pipe(d).pipe(c);Lancez le serveur et lorsque vous exécutez le client, vous devriez voir :
$ node client.js
beep => BOOPLe client à envoyé 'beep' à la fonction transform() du serveur et le serveur a appelé la fonction de 'callback' du client avec le résultat, élégant !
L'interface de flux que dnode fourni ici est un flux duplex puisque le client et le serveur sont connectés l'un à l'autre ( c.pipe(d).pipe(c) ) avec les requêtes et les réponses échangées dans les deux sens.
Là où ça devient fou, c'est quand vous commencez à passer des arguments de fonction qui chaînent des fonctions de 'callback'. Voici une version mise à jour du serveur précédant avec une cinématique d'appels des fonctions de 'callback' emboîtés :
var dnode = require('dnode');
var net = require('net');
var server = net.createServer(function (c) {
var d = dnode({
transform : function (s, cb) {
cb(function (n, fn) {
var oo = Array(n+1).join('o');
fn(s.replace(/[aeiou]{2,}/, oo).toUpperCase());
});
}
});
c.pipe(d).pipe(c);
});
server.listen(5004);Voici le client mis à jour :
var dnode = require('dnode');
var net = require('net');
var d = dnode();
d.on('remote', function (remote) {
remote.transform('beep', function (cb) {
cb(10, function (s) {
console.log('beep:10 => ' + s);
d.end();
});
});
});
var c = net.connect(5004);
c.pipe(d).pipe(c);Après avoir relancé le serveur (nouvelle version), voilà ce que nous obtenons en exécutant le client :
$ node client.js
beep:10 => BOOOOOOOOOOPÇa fonctionne, tout simplement !
L'idée de base, c'est qu'il vous suffit de placer des fonctions dans des objets et de les appeler depuis l'autre côté d'un flux pour que les fonctions puissent faire les allers-retours et prendre leur place dans l'enchaînement des appels comme si le processus était local. Le plus extraordinaire, c'est que lorsque vous passez des fonctions à des fonctions souches en tant qu'arguments, ces fonctions se retrouvent en qualité de souches de l'autre côté !
Cette approche qui consiste à empiler des appels de fonctions récursivement est désormais connue sous le nom de la "manœuvre des tortues qui se marchent sur la carapace". La valeur de retour de chacune de ces fonctions sera ignorée et seule une énumération des propriétés des objets sera envoyée, façon JSON.
C'est la pyramide des tortues !
Comme dnode s'exécute dans node.js ou dans un navigateur à travers n'importe quel flux, il est facile d'appeler des fonctions définies n'importe où, et particulièrement utiles lorsqu'elles sont associées avec mux-demux pour multiplexer un flux RPC afin de contrôler un flux de données très volumineux.
X. Combiner pour plus de puissance▲
X-A. Une discussion instantanée (chat)▲
Le module append-only nous apporte un tableau append-only (ajout uniquement) confortable par-dessus la couche scuttlebutt qui permet d'écrire très simplement un chat distribué et cohérent entre plusieurs nœuds pouvant survivre à des coupures partielles du réseau.
Voyons comment implémenter ce chat.
X-B. Écrire vos propres socket.io▲
Nous pouvons construire une API pour émettre des événements à la mode Socket.io en utilisant les flux vus plus haut dans cet article.
Tout d'abord, nous pouvons utiliser shoe pour créer un nouveau gestionnaire de websocket côté serveur et avec emit-stream qui transformera un émetteur d'événements en un flux qui émet des objets. Le flux objet peut alors être alimenté par JSONStream pour sérialiser des objets, et de là, le flux sérialisé peut être raccordé à un navigateur distant.
var EventEmitter = require('events').EventEmitter;
var shoe = require('shoe');
var emitStream = require('emit-stream');
var JSONStream = require('JSONStream');
var sock = shoe(function (stream) {
var ev = new EventEmitter;
emitStream(ev)
.pipe(JSONStream.stringify())
.pipe(stream)
;
...
});Dans la fonction de 'callback' de shoe, nous pouvons émettre des événements pour la fonction ev. Ici, nous ne ferons qu'émettre différents types d'événements à intervalles réguliers :
var intervals = [];
intervals.push(setInterval(function () {
ev.emit('upper', 'abc');
}, 500));
intervals.push(setInterval(function () {
ev.emit('lower', 'def');
}, 300));
stream.on('end', function () {
intervals.forEach(clearInterval);
});In fine, l'instance de shoe devra juste être liée au serveur http :
var http = require('http');
var server = http.createServer(require('ecstatic')(__dirname));
server.listen(8080);
sock.install(server, '/sock');Pendant ce temps, côté navigateur, il suffit de parser le flux shoe json et de transmettre le flux objet résultant à eventStream(). eventStream() ne fait que retourner un émetteur d'événements qui les émet coté serveur :
var shoe = require('shoe');
var emitStream = require('emit-stream');
var JSONStream = require('JSONStream');
var parser = JSONStream.parse([true]);
var stream = parser.pipe(shoe('/sock')).pipe(parser);
var ev = emitStream(stream);
ev.on('lower', function (msg) {
var div = document.createElement('div');
div.textContent = msg.toLowerCase();
document.body.appendChild(div);
});
ev.on('upper', function (msg) {
var div = document.createElement('div');
div.textContent = msg.toUpperCase();
document.body.appendChild(div);
});Utilisez browserify pour compiler le code source du navigateur afin que vous puissiez appeler require() sur tous ces modules malins côté navigateur :
$ browserify main.js -o bundle.jsIl ne reste plus qu'à indiquer <script src="/bundle.js"></script> dans le code html et l'exécuter dans un navigateur pour voir les événements côté serveur se propager côté navigateur.
Avec cette approche orientée flux, vous pouvez vous fier à des composants légers et réutilisables qui ont juste besoin de savoir comment dialoguer avec un flux. Au lieu de router des messages à travers un système de gestion globale d'événements à la mode socket.io, vous pouvez vous concentrer sur le fractionnement de votre application en petites unités qui implémentent correctement une fonctionnalité unique.
Par exemple, vous pouvez trivialement remplacer JSONStream dans cet exemple stream-serializer pour obtenir une sérialisation différente pour un codage différent. Vous pouvez abandonner les couches au-dessus de shoe pour gérer les reconnexions et pulsations de réseau, et utiliser des interfaces simples de streaming. Vous pouvez même ajouter un flux dans une chaîne pour utiliser namespaced events avec eventemitter2 au lieu de EventEmitter du noyau.
Si vous voulez des flux différents qui agissent de façon différente, il sera également avantageusement simple d'exécuter mux-demux à travers cet exemple pour créer des canaux dissociés pour chacun des différents types de flux dont vous avez besoin.
Au fur et à mesure de l'évolution de vos spécifications, vous pourrez remplacer ces composants orientés flux autant que cela sera nécessaire sans les risques liés aux frameworks dogmatiques.
X-C. Les flux html pour les navigateurs et serveurs▲
Nous pouvons utiliser des modules de streaming pour réutiliser la même logique de rendu pour les client/serveur html. Cette approche est indexable, compatible SEO, et nous apporte les mises à jour en temps réel.
Notre renderer prend des lignes de json en entrée et retourne des chaînes html en sortie. Le texte, l'interface universelle !
Render.js :
var through = require('through');
var hyperglue = require('hyperglue');
var fs = require('fs');
var html = fs.readFileSync(__dirname + '/static/row.html', 'utf8');
module.exports = function () {
return through(function (line) {
try { var row = JSON.parse(line) }
catch (err) { return this.emit('error', err) }
this.queue(hyperglue(html, {
'.who': row.who,
'.message': row.message
}).outerHTML);
});
};Nous pouvons utiliser brfs pour appeler à la volée fs.readFileSync() pour le code navigateur et hyperglue pour mettre à jour le html basé sur des sélecteurs css. Vous n'avez pas nécessairement besoin d'utiliser hyperglue ici ; tout ce qui peut retourner une chaîne avec du html à l'intérieur marchera.
Le fichier row.html utilisé n'est qu'un simple stub (souche) :
row.html :
Le serveur utilisera juste slice-file pour que tout reste simple. slice-file est à peine plus évolué que la célèbre API tail/tail -f avec en plus des interfaces en osmose avec les bases de données relationnelles et NoSQL comme CouchDB
server.js :
var http = require('http');
var fs = require('fs');
var hyperstream = require('hyperstream');
var ecstatic = require('ecstatic')(__dirname + '/static');
var sliceFile = require('slice-file');
var sf = sliceFile(__dirname + '/data.txt');
var render = require('./render');
var server = http.createServer(function (req, res) {
if (req.url === '/') {
var hs = hyperstream({
'#rows': sf.slice(-5).pipe(render())
});
hs.pipe(res);
fs.createReadStream(__dirname + '/static/index.html').pipe(hs);
}
else ecstatic(req, res)
});
server.listen(8000);
var shoe = require('shoe');
var sock = shoe(function (stream) {
sf.follow(-1,0).pipe(stream);
});
sock.install(server, '/sock');La première partie du serveur prend en charge la route / et envoie les cinq dernières lignes depuis data.txt vers la div #rows.
La seconde partie du serveur prend en charge les mises à jours en temps réel vers #rows en utilisant shoe, une simple prothèse d'émulation de websocket .
Ensuite nous pouvons écrire du code navigateur simple pour peupler les mises à jour temps réel depuis shoe vers la div #rows
var through = require('through');
var render = require('./render');
var shoe = require('shoe');
var stream = shoe('/sock');
var rows = document.querySelector('#rows');
stream.pipe(render()).pipe(through(function (html) {
rows.innerHTML += html;
}));Reste à compiler avec browserify et brfs :
$ browserify -t brfs browser.js > static/bundle.jset le tour est joué ! Maintenant, nous pouvons peupler data.txt avec des données inutiles :
$ echo '{"who":"substack","message":"beep boop."}' >> data.txt
$ echo '{"who":"zoltar","message":"COWER PUNY HUMANS"}' >> data.txtpuis, lançons le serveur :
$ node server.jset rendons-nous à l'URL http://localhost:8000 pour y voir notre contenu. Si nous en ajoutons :
$ echo '{"who":"substack","message":"oh hello."}' >> data.txt
$ echo '{"who":"zoltar","message":"HEAR ME!"}' >> data.txtalors la page s'actualise automatiquement en temps réel avec la mise à jour, hourra !
Maintenant, nous utilisons exactement la même logique de rendu sur le client comme sur le serveur pour présenter du contenu compatible SEO et indexable en temps réel. Hourra !
XI. Note de la rédaction de Developpez.com▲
Ce tutoriel est la traduction de How to write node programs with streams.
Nous tenons à remercier Autran pour la traduction, Chrtophe et Winjerome pour leurs diverses remarques et corrections et Jacque_jean pour la relecture orthographique.
